Built for traders who want the keys.
Every signal, filter, and gate is configurable and inspectable. The screenshot below is one tab — there are sixteen more.
How CORE thinks.
Most trading software treats the market as a stream of indicator readings. CORE treats it as a structured object — channels, regimes, band geometry, multi-timeframe state — and runs every decision through a deterministic pipeline you can inspect at every stage.
Market structure
Parallel channels, rainbow bands, geometric state. Six timeframes in parallel.
Regime detection
Trend / range / divergence per TF. HTF context and alignment scoring.
Trade Policy
Composable rules across 31 dimensions. BLOCK, ALLOW, REVERSE per signal.
ML confidence
XGBoost classifier on 41 features. Per-trade confidence, OOD detection.
Local execution
Hardware-bound, encrypted models, signed binaries. Native exchange routing.
Diagnostics & replay
Per-decision drivers, full replay viewer, validation suite re-runnable on your data.
Every stage is independently auditable and independently toggleable. Run the policy layer alone for rule-based trading. Add ML scoring as a confirmation gate. Or stack the Pro layers (Rainbow Policy v2, Stretch Policy) on top for parallel signal streams. The pipeline is the same; what you put through it is yours to configure.
What's under the hood.
Five pillars, each with its own thesis. None of them are cosmetic, none of them are bolt-ons. Auditable, testable, documented in the included reference.
Trade any timeframe. Switch on the fly.
Every timeframe is a first-class citizen — there's no "real" TF the system is built around with the others as bolt-ons. The same engine that finds 1-minute scalps finds daily swings. The same policy layer governs both. The same ML pipeline scores both. Switching scope is a configuration choice, not a redeploy.
Signal generation
A strategy builder, not a black box. Six independently-implemented base strategies that you compose into a complete signal pipeline — any one as the trigger, any other as a confirmation gate. The composability is the point: structural-channel logic confirmed by band crossover, or RSI strategy gated by parallel-channel context. The strategies are the alphabet; you write the language.
- Parallel Channels / PC Hybrid / PC Breaks — three flavours of channel-break detection, with two distinct engines (AUTO with DAR + wave anchoring, or MANUAL parameterised regression-fit).
- Band Crossover — 4-band rainbow system (A/B/C/D) with configurable trigger pairs, cross styles (penetrate / fully cross), per-band position and angle filters.
- Band Bounce — touch-and-react logic on the rainbow A-band with RSI confirmation and slope filters.
- RSI Strategy — configurable OB/OS thresholds with turning detection, importable as either a base or a confirmation lane.
- Composable filters — any base strategy can be stacked as a confirmation on any other (e.g. PC break confirmed by band crossover, or band bounce gated by RSI zone). Per-side, per-TF.
Trade Policy & filtering
A composable decision layer that turns market structure into execution rules. Thirty-one filter dimensions — regime, RSI, slope, volume, PC quality, rainbow context, HTF alignment — combinable per signal type, per timeframe, with three deterministic actions. Rules are JSON, version-controllable, exportable. The policy layer is the discipline: it enforces what you decided when you weren't trading, on the trades that come when you are.
- 31 filter dimensions: regime states, RSI zones, slope buckets, ATR/vol buckets, PC qualities, rainbow context, HTF alignment, and more.
- Quick TF Gate — multi-timeframe selection auto-generates blocking rules.
- Stretch policy bypass — independent signal layer for band-stretch transitions.
- Archetype gating — load a clusters CSV, restrict trades to recognised setups.
ML pipeline & workshop
Confidence scoring, not signal generation. The XGBoost classifier doesn't decide what to trade — the strategy and policy layers do that. The model assigns a probability of profit to candidate signals, and you choose the threshold that controls how aggressive the system is. ML Workshop lets you search for the feature subset that performs best out-of-sample, validate any candidate model against six orthogonal methodologies, and verify that what runs live matches what passed validation.
- 41-feature engineering surface — structural, regime, PC channel, multi-timeframe context.
- Automated feature search with composite scoring — hard floors on n/month, win rate, max drawdown, holdout disagreement.
- Auto-retrain at configurable intervals; SGD partial-fit between full retrains.
- Models versioned as preset bundles — share, audit, roll back.
- Live-vs-replay 2×2 contingency to verify deployed model matches research.
Advanced policy layers PRO
Two parallel decision systems that see things the base pipeline cannot. Rainbow Policy v2 enforces structural rules in a locked evaluation order — TF, regime, direction, band, lreg, geo — making the system act on archetype-level setups rather than per-tick reactions. Stretch Policy is its own signal generator: a separate model with a 46-feature encoder dedicated to band-stretch geometry, identifying the deformed-band scenarios the base strategies don't have language for.
- Rainbow Policy v2 — rule-first structural policy with locked evaluation order (TF → regime → direction → band → lreg → geo → optional). Divergence cells, archetype presets, HTF-overrule guards.
- Stretch Policy — a parallel signal generator with its own ML model and a 46-feature encoder dedicated to band-stretch geometry (gap ratios, arm/geo tau, geo_state). Generates signals the base strategies would never see — A-C transitions, A×B crosses, deformed-band scenarios. Trains separately.
What using CORE looks like.
A research-and-deployment loop, not a one-click bot. The sequence below is how a model goes from raw historical data to live execution — four phases, each with its own outputs, each independently inspectable. You can stop after any phase. You can re-enter from any phase. Most operators iterate phases 2 and 3 several times before deploying.
Generate snapshots from historical data
In the Live Trading tab, download a bootstrap window sized to your hardware and your patience — bigger windows mean richer training data and longer compute. Set your signal scope (e.g. 5m, 15m, 1h) and run with ML frozen: no retraining, just the existing logic running through history.
What you get out: ML snapshots capturing every candidate signal in a fully-featured form, plus a trade audit reconstructing the exact decisions the system made at every bar. These are the raw materials for everything downstream.
- ml_snapshots.jsonl
- trade_audit_v2.jsonl
- xai_explain.jsonl
Find the model in ML Workshop
Open ML Workshop, point it at your snapshots, and run a Check Model on a baseline feature set. Compare single-TF training to multi-TF combinations — adding context from other timeframes is often where the signal comes from. The validation numbers don't lie: you'll see exactly which combination produces a model that holds up out-of-sample.
When you have a baseline that's working, set hard floors (n/month, win rate, max drawdown, holdout disagreement) and hit Search Model. CORE explores feature subsets via backward elimination and swap perturbation, scoring each candidate against your floors. The model that comes out is often not the one you'd have built by hand — and often performs better.
- CPCV
- Walkforward
- Quarterly hold-out
- Monte Carlo
- Timeshift gate
- Reverse-trade gate
Verify on data the model has never seen
Take fresh data from after the training window, run an independent walkforward through it in ML Workshop. The output mirrors exactly what you'd see if you'd run the model live on that period — no leakage, no peeking, just the model meeting unseen reality.
This is the phase that tells you whether the search-found model is real or whether it found patterns that won't repeat. If the validation report and the independent walkforward agree, you have a deployable model. If they disagree, back to phase two — that's the loop.
- fresh-data WR
- per-threshold PnL
- regime stability
- per-TF performance
Deploy to live execution
Back to Live Trading. Download a smaller bootstrap — just enough to warm the most demanding feature window. Upload your validated model, set it frozen (no retrain), choose your position size, leverage, and entry style (maker-hybrid for zero-fee fills if your venue supports it).
In Autonomous, set your minimum confidence threshold and a daily trade cap, then enable Auto Trade. The system walk-forwards through your bootstrap while fresh bars stream from the exchange. Once it catches up to the live edge, execution begins. From there it's a research-and-monitoring rhythm: check diagnostics daily, retrain on accumulated audits weekly or monthly, adjust policies as regimes shift.
- min confidence
- trades / day cap
- position size
- leverage
- maker-hybrid entry
- daily loss limit
The architecture isn't a guess. It's the residue of 50+ documented research scripts, calendar stress tests across multiple market regimes, and the failures those tests surfaced. What you see is what survived.
A look inside.
Three real tabs from a live build. The rest — autonomous training, live trading, analytics, diagnostics, XAI viewer — you'll see on day one.
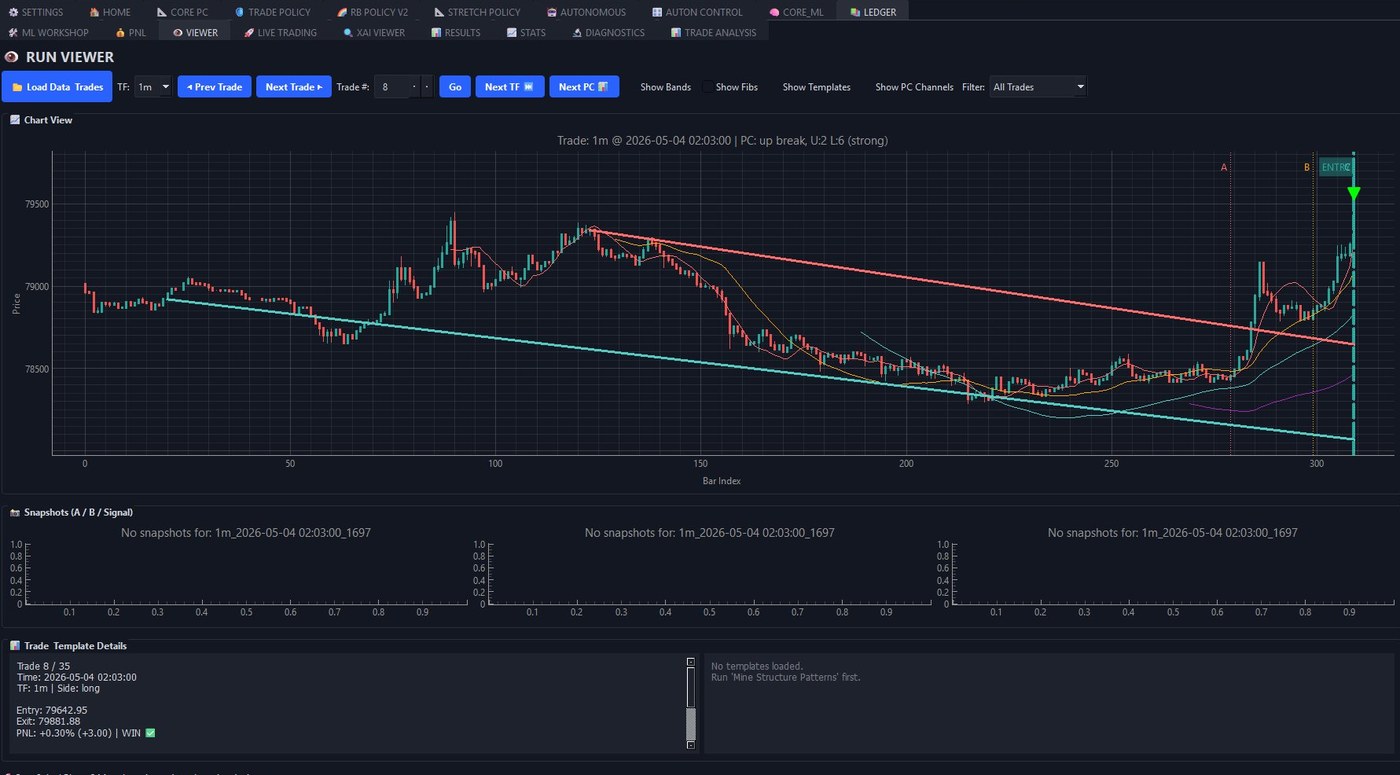
See every trade. Every channel. Every break.
Replay any historical run with structural overlays in place. PC channels, entry and exit markers, the full trade-outcome panel. Step through trade-by-trade, or jump to any TF.
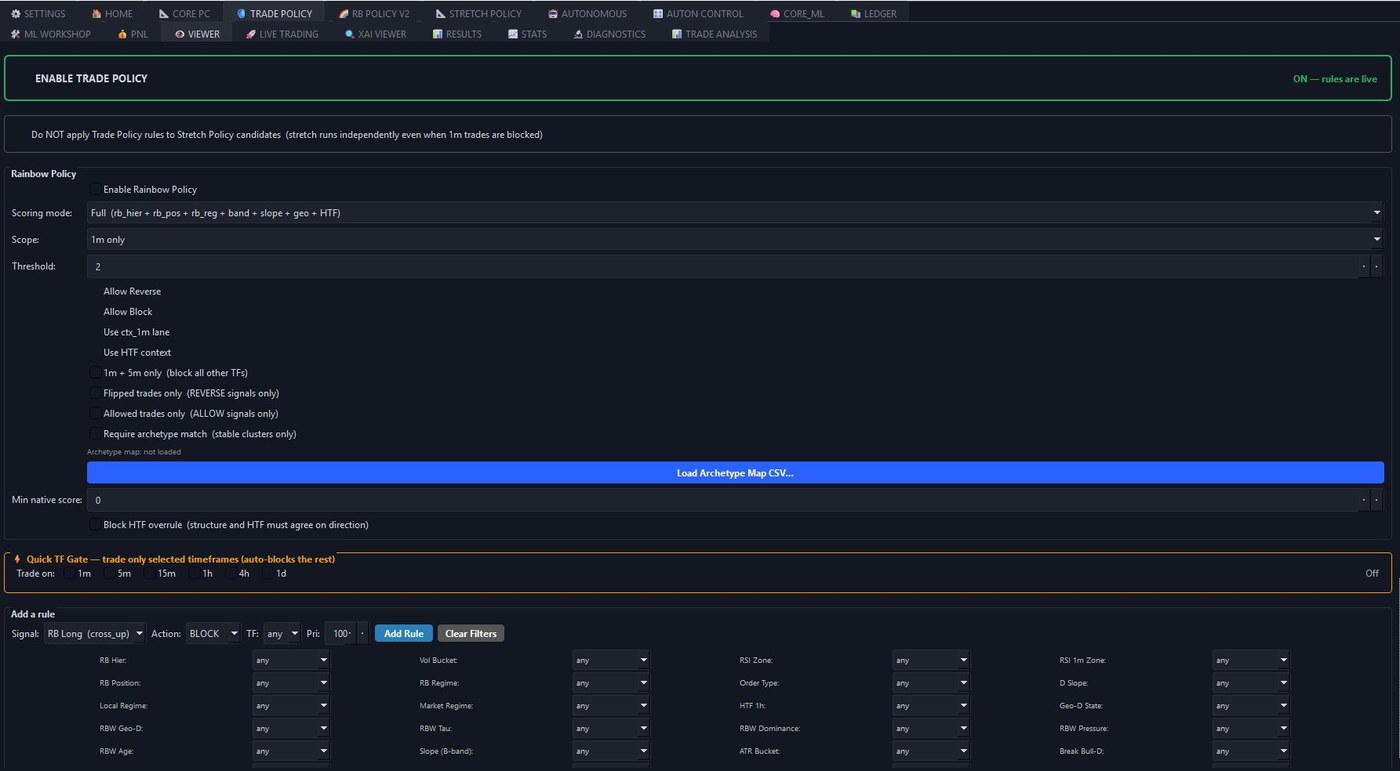
Compose rules. Block the noise. Allow the edge.
The decision layer that turns market structure into execution discipline — 30+ filter dimensions, three actions, all combinable per signal type and timeframe.
Six validation methodologies. One checkbox row.
Run the full validation suite from a single workflow. CPCV, Walkforward, Timeshift, Reverse-trade, MonteCarlo, Quarterly hold-out — all wired into the same pipeline that ships with every model.

Validation, not vibes.
Every model ships with a validation report. Numbers below are from a recent non-optimised reference model trained on 5m + 15m + 1h data, ~17k training snapshots, evaluated on roughly 5k held-out trades per quarter. Methodology and dataset are described in the report, which is included with each model preset.
Quarterly hold-out — every trade scored once, fully out-of-sample
| Threshold | Trades | Win rate | Avg PnL | Sum PnL |
|---|---|---|---|---|
| 0.50 | 794 | 53.1% | +0.28% | +223.1% |
| 0.55 | 278 | 60.4% | +0.40% | +111.2% |
| 0.60 | 77 | 67.5% | +0.49% | +37.6% |
| 0.65 | 20 | 70.0% | +0.54% | +10.8% |
Both win rate and average per-trade PnL improve monotonically with the confidence threshold — the score is doing real work, picking better setups rather than just smaller ones. Sample size shrinks at higher thresholds, as expected; per-trade economics keep improving.
Walkforward — same numbers, different methodology
| Train window | Trades / yr | Win rate | Avg PnL | Net annualised |
|---|---|---|---|---|
| 12 months | 524 | 52.8% | +0.28% | +117.3% |
| 9 months | 608 | 50.9% | +0.25% | +116.3% |
| 6 months | 770 | ~50% | +0.22% | +121.9% |
| 3 months | 964 | 42.1% | +0.14% | +30.1% |
Three different train-window sizes converge on roughly the same number — that's the consistency signal. The 3m window underperforms because the model needs more training history to stabilise; longer windows recover. All numbers are at threshold 0.50, which is intentionally permissive to keep sample sizes meaningful.
Methodology
Quarterly hold-out
The trading period is split into 4 quarters. For each quarter, the model is trained on the other three and evaluated on the held-out quarter. Every trade is scored exactly once, on data the model has never seen. This is the most rigorous out-of-sample test in the suite.
Walkforward
Rolling-window simulation. Train on N months, evaluate on the next month, advance, retrain. Closest analogue to live operation: model never sees future data, retrains on a fixed schedule. Reported across train windows of 3 / 6 / 9 / 12 months for stability comparison.
Combinatorial Purged Cross-Validation (CPCV)
10 batches × 45 combos with embargo periods between train and test slices. Detects look-ahead bias. Treated as a sanity check, not a primary metric — CPCV is known to be optimistic versus walkforward.
Monte Carlo permutation test
Real CPCV baseline run alongside 200 permutations of shuffled labels. If the model performs no better on real data than on randomly relabelled data, the apparent edge is luck — the test rejects it. Adds a bootstrap 95% confidence interval around the real win rate. Reports a p-value and a verdict (significant / marginal / not significant). The reference model passes at p < 0.05.
Reverse-labels gate
Train the model on losses labelled as wins and wins as losses. A leaking model — one that's accidentally seeing future information — will still pick the inverted winners and post a high WR. A clean model collapses to chance. Reference model passed: 26.1% WR vs the 60% threshold for failure.
Timeshift gate
Shift labels forward by 20 / 50 / 100 bars and retrain. A leaking model still picks future winners through the shift; a clean one drops to noise. Reference model passed: 0% WR at all shifts.
Pricing.
Monthly subscription — keeps you on the latest build, the latest models, the latest validation tooling. Pay annually and save up to 25%. Live sales open Q3 2026 — reserve your spot below.
- All trading subsystems unlocked
- Full backtest + walkforward suite
- ML Workshop with feature search
- Live execution disabled
- Hardware-bound licence
- Everything in Trial
- Live execution enabled (MEXC)
- XGBoost + auto-retrain pipeline
- Trade Policy with all 31 filters
- XAI viewer + trade analysis
- Hardware-bound licence (1 machine)
- Rainbow Policy v2 / Stretch Policy
- Everything in Standard
- Rainbow Policy v2 — rule-first structural layer
- Stretch Policy — parallel signal engine
- Multi-venue execution (Binance, Bitget)
- Two machines per licence
- Priority email support
Reserve your spot.
CORE launches Q3 2026, capped at 100 Pro licences. Three ways to get on the list. Email goes nowhere except your inbox when there's actual news.
Just tell me when it's live.
No commitment. One email at launch, one at major milestones. Unsubscribe in one click.
- Notified before public launch
- Launch pricing locked at signup
- Zero spam, no upsells
One of the first 100 Pro users.
Reserve a Pro launch licence. We'll contact you when sales open. No payment now — this is just your spot in the queue. Cap is real: when 100 are reserved, the list closes.
- Guaranteed access to Pro at launch
- Launch pricing locked at signup
- Priority onboarding + support
- Listed in the founding cohort (opt-in)
Help shape it. Get half off.
Run pre-launch builds. Find bugs. Give honest feedback. We need ~2 hours/week. Not a casual signup — quiet ghosters get their slot reassigned.
- 50% off any tier for 6 months at launch
- Direct line to the developer during testing
- Founding tester credit in the app (opt-in)
- First look at every new feature
We read every application. Selected testers will be contacted within 7 days.
Questions.
If yours isn't here, the answer is probably yes.